Abstract
这篇论文来自牛津大学, 讲述了如何利用RNN(Recurrent Neural Network)循环神经网络模型来进行原始码混淆.
本来代码编译完就应该是机器码可以变成汇编但不容易还原, 但那种解释型语言用解释器去解释源代码执行的就倒霉了, 还有java这种编译生成对人类阅读比较友好的字节码再给虚拟机执行. 所以这种情况下就体现出了源代码混淆的价值, 让代码可以跑但看不到具体怎么写的.
Seq2seq本来是用来进行翻译的, 这篇论文把这个用来进行代码加密.
先快速回想一下关键技术的原理吧
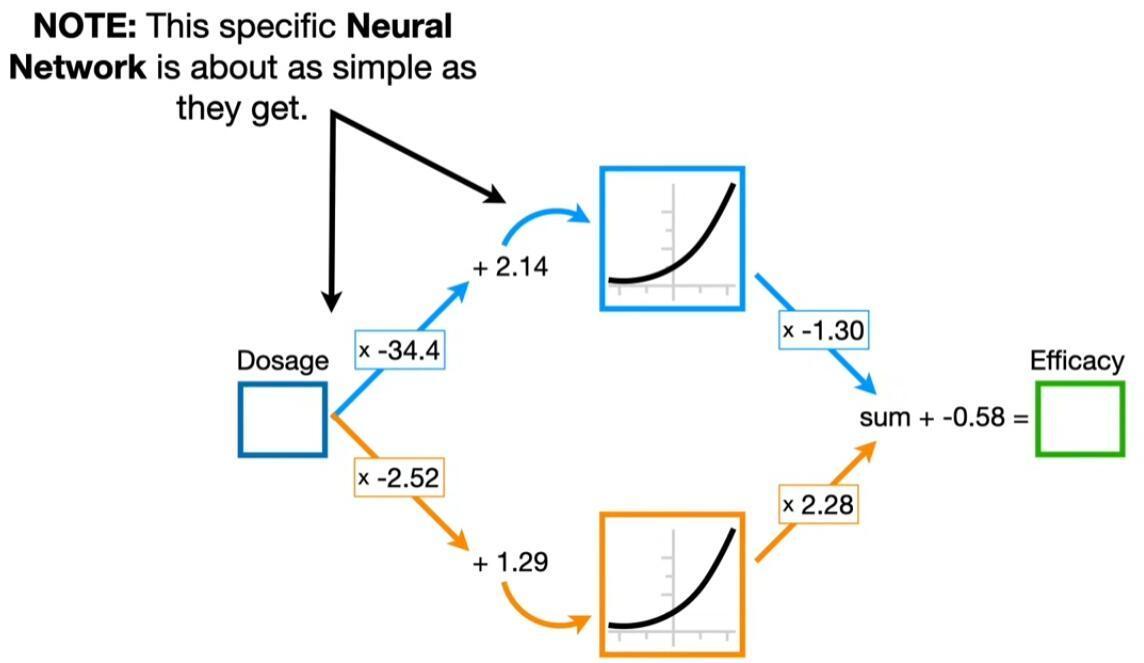
传统的神经网络模型对于输入的向量, 进行权重计算输入下一层, 算了很多层后得出了结果, 跟实际结果比较再算出损失值, 再想办法让损失值变成比较小的前提下计算导数乘以步长就是学习率.
有很多训练数据的话, 同时计算多个数据的预测值得出损失函数, 这样就能训练的更好.
要注意的是本来这样跟权重或Biases去乘乘加加得出来的还是直线或者说高维空间的一个平面, 加一个激活函数就变成弯的了, 这样很多弯的高位平面叠加就能围成各种形状的高维空间来进行分类预测.
这确实是人工智能, 但这种做法缺点也很明显, 那就是输入数据的格式被定死了.
比如说预测伪随机数抽卡的<原X Imp*ct>下一次抽卡的出货概率, 用很多的抽卡情况作为训练数据, 作为输入数据的之前的抽卡情况肯定是各种各样的, 比如抽70次的预测出货概率肯定应该比抽20次的预测概率要高 (指的是因为伪随机数抽卡, 如果之前的抽卡情况都没出货, 则预测第71抽会比第21抽的出货概率更高). 但传统的神经网络模型就只能预测某个固定次数的, 因为就像上图里面的显示的输入数据的格式已经被固定了.
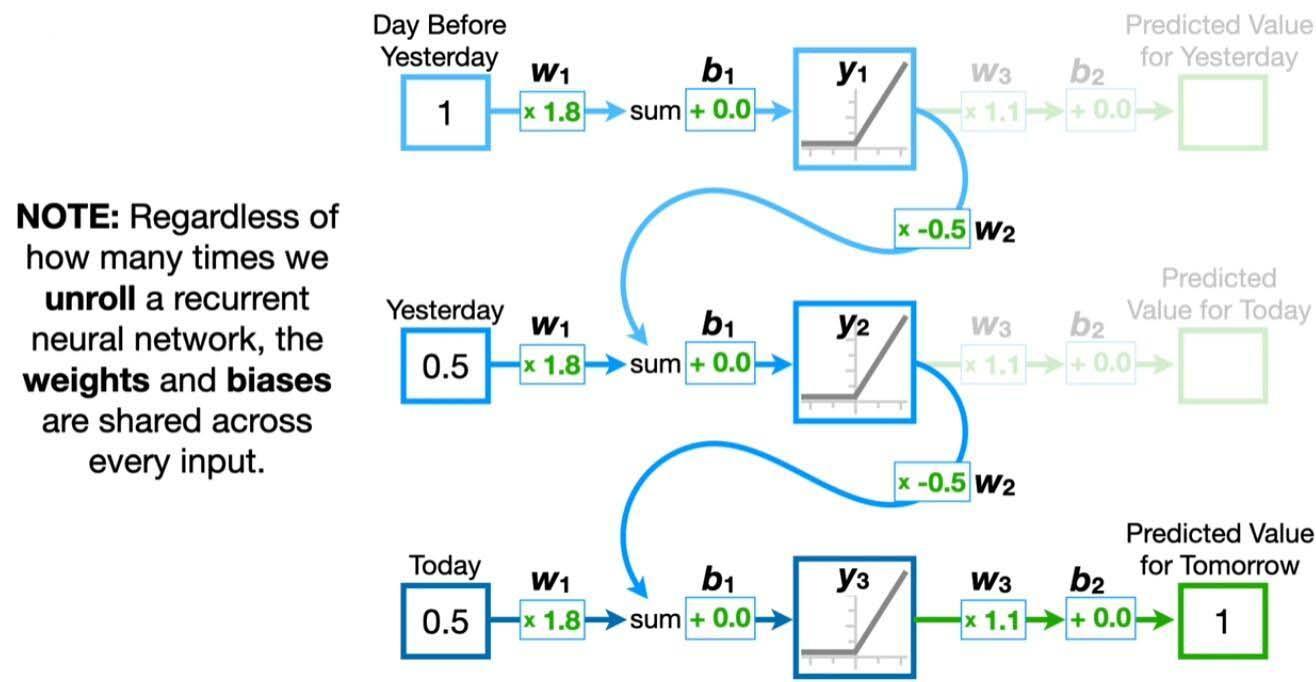
循环神经网络模型就不一样了, 把一次训练的输入数据也当作是序列一个一个来, 同时一次预测的输入不仅有当前输入数据, 还有上一次预测输出的feedback loop.
这就使得能接受不同长度的训练数据输入, 而且每次的输出都是和之前全部的输入相关联的.
但要注意RNN还有 gradient vanishing/exploding 的问题, 就是因为如果层数很深的话, feedback loop的系数就会不停的叠乘导致求导数的时候权重的变化量要么就很大要么就很小, 猜一猜这个论文是优化过的或者还用了 transformer 模型.
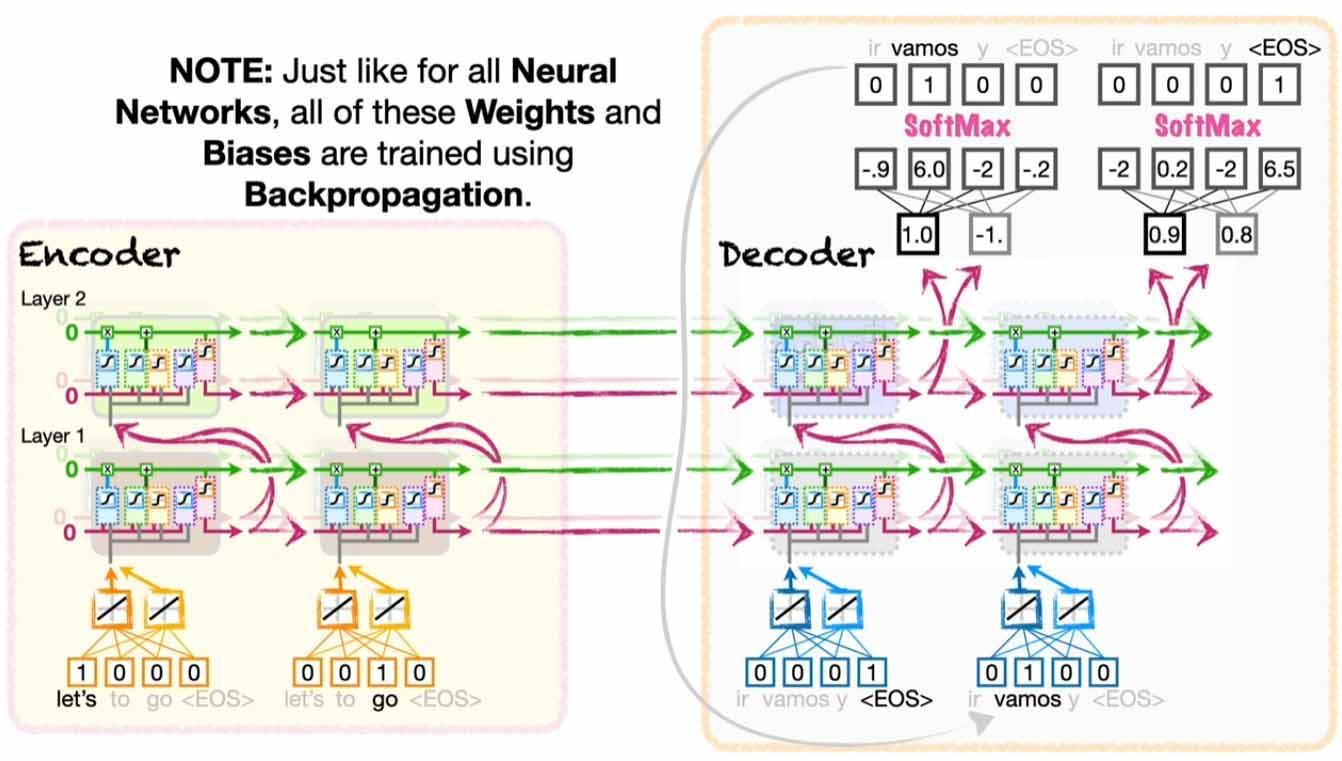
如果有俩个RNN的话, 就能实现Seq2seq了. 先把输入的 sequence 给第一个RNN(Encoder), 最终就能得到一个 context vector.
再把start of sentences符号(或end of sentences)和上一步的vector作为起始的输入和feedback, 让第二个RNN(Decoder)来进行预测给输出, 就和普通的RNN一样开始 unroll 但不同的是输入数据不是给定的而是上一次roll出的预测输出(训练的时候如果上面预测错了就还是用真实值做输入).
把第二个RNN的输出连起来, 就是对第一个RNN输入的sequence实现了Seq2Seq.
接着就开始看看论文吧, 开头先说了传统的原始码混淆方法这个都是老生常谈了.
然后再说了有四种 metric 评估代码混淆的效果
- Code Potency 这个就是主要衡量代码复杂程度的, 比如算算流程图的边和节点数量, 或者变量数量和嵌套深度之类的.
- Resilience 混淆后的代码能抵御自动化软体还原的能力
- Stealth 抵御人工还原的能力
- Execution Cost 额外花费的时间成本, 既包括代码混淆的成本, 也有执行混淆代码对比原来直接执行额外花费的成本
然后说明了一下什么是RNN Encoder-Decoders or sequence-to-sequence model 这个上面也回想过了, 他们发明了一种用深度学习技术给代码进行加密的方法, 模型就是加密和解密的密钥.
Content
Chapter 1
他们用了俩个Seq2seq模型也就是四个RNN, 一个用于加密原始码, 一个用于解密加密.
先创建一个Full Characters Set就是包括了所有的字符的集合(但毕竟都是代码的字符所以大小也不会超过ASCII表), 然后创建一个给character返回index的字典和一个给index返回character的字典.
这样就能把原始码变成一串数字的sequence了, 再丢到一个权重都是随机的RNN模型里面, decoder再根据context vector生成密文输出.
这里他们也不需要 word embedding, 因为无论输出什么样子的加密都没关系.
然后再把很多的原始码sequence和第一个Seq2seq生成的加密数据丢给第二个Seq2seq模型训练, 经过千锤百炼后第二个模型能根据密文还原出原始的输入sequence了.
再把第二个模型生成的sequence依照index返回character的字典给还原, 这样就成功得到了原始码.
他们再尝试这个还原出来的原始码能否被执行, 如果可以执行就保留这个加密代码和俩个密钥.
不能执行就重新训练.
卧槽这意思是密钥还是一次性的😲, 因为他们也说了是迭代的2000次训练的模型.
也就是不是用2000个原文和密文来训练, 而是一个原文和密文训练了2000次.
这样密钥对确实就是一次性的, 如果用同一个加密模型去加密别的原始码, 之前能用的解密模型也会解密不了.
猜一猜这样做是因为如果要泛用的解密模型那模型会需要非常大, 而且要训练很久🧐.
Chapter 2
为了评估上一步的成果对比传统方法的效果, 他们将会评估Stealth和Execution Cost.
因为密文对比原始码根本是indistinguishable, 所以Code Potency或者是Resilience这种需要对比原始码和加密后的就不applicable.
Stealth
他们就算了从混淆代码到原始码的Levenshtein距离, 简单来说就是混淆代码需要经过多少次字符变换才能还原成原始码.
他们对比了AI的混淆代码和International Obfus-cated C Code Contest (IOCCC)大赛的混淆代码, 看他们的表格大约提高了26%的Stealth吧.
Execution Cost
他们随机生成长度1~4000的字符串来模拟原始码, 然后记录六个信息, 看看他们有什么关系.
- Length of string input
- Randomness metric (Levenshtein distance)
- Execution time for encryption
- Execution time for decryption
- Character variation
- Average character length of ciphertext
这六个变量就是字面上的意思, 实验环境是GTX 1070的Win10.
后面是五个表格, 大概意思是说加密的cost和原文长度没关系, 解密的训练和原文是线性关系, 密文长度和原文没有关系.
后面还算了一下这种面对这种三层模型, 攻击者要逆向还原的计算量有多大, 怎么算的霸天看不懂, 总之就是不可能被破解就是了
啊看表格, 如果最长的4000字符需要14000毫秒训练, 那还不错啊, 反正这个模型也是一次性的, 用在重要的代码加密上就行了.
而且这个还是1070跑的效果, 这个利用AI来进行代码加密混淆的办法确实很不错👏.
Conclusion
好论文!👍 不愧是牛津大学出品.
而且这个也不止能加密源代码, 只要定位是重要且不会变化的东西的话什么都能加密, 以后手动加密什么手动代码混淆就直接弱爆了!😭
任何东西都能丢给AI生成俩个模型当作密钥🤗, 当然唯一缺点就是不能太长了, 不然训练需要的时间会爆炸.